Zero Redundancy Optimizers: A Method for training Machine Learning Models with Billion Parameters
Hitesh Patel, Hossein Chaghazardi & Iman Zadeh
Oracle Cloud Infrastructure, Artificial Intelligence Services (OCAS)
hitesh.laxmichand.patel@oracle.com
Introduction
A Deep Neural network requires a lot of computing resources and time for training. Large models generally provide better accuracy on respective benchmarking datasets but training a model with millions of parameters with the best GPU resources and infrastructure set is still very challenging since fitting a model takes almost all the memory on a GPU (ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, 2019). Sometimes, very large models cannot even fit on a single GPU since the memory on a GPU is 16/32 Gb, and a Model of size 1000 Million parameters can take at least 16 Gb of memory. ZeRO is a technique that eliminates memory redundancies by partitioning the optimizer, gradient, and parameters rather than replicating them to utilize the whole available memory. ZeRO optimization helps to train bigger models and fit more data by minimizing the memory required to fit a model than other distributed training methods.
In this blog, we will be covering.
- A summary of the main idea behind the Zero Redundancy Optimizers (ZeRO) approach for memory optimization on a GPU and faster training of very large models.
- An example of training and evaluating a model using the Fairscale Library which has an implementation of ZeRO redundancy optimizers.

Brief Overview of Zero Redundancy Optimizer
In general, the model state (including, model’s optimizer, gradient, and its parameters) occupies a large amount of memory on a GPU which causes a memory bottleneck (shortage) when loading and training a model that has a large number of parameters.
Existing solutions such as Model Parallelism (MP) or Data Parallelism (DP) provide excellent computational efficiency. Data Parallelism is used when the model can fit into a single GPU, while Model Parallelism is used when the model cannot fit into a single GPU but both have limitations in fitting a very large model.
In Model Parallelism, computations and parameters of each layer in a model are split vertically into multiple GPUs. Each GPU has a model partition and is trained on a batch of data by communicating with different layers of a model residing on different GPUs during the forward and backward passes.
In DP, the same model gets replicated on all GPUs where each GPU runs a single process, and a master process controls the communication between the GPUs. In DP and at each step, a mini-batch of data is divided equally among the GPUs. Each process performs the forward and backward pass on a subset of data and uses averaged gradients across processes to update the model on each GPU. You can read more about Data Parallelism and steps to set up DP in PyTorch in our previous blog here.
DP does not reduce the memory per device since the model is replicated on every GPU. Model parallelization works well when the model is on a single node where inter-GPU communication is high. Still, communication efficiency quickly degrades when we scale to multiple GPUs residing on a different node as multiple factors such as network bandwidth can delay the communication between the GPUs during the forward and backward propagation.
- DP has good compute/communication efficiency but poor memory efficiency.
- MP has good memory efficiency but poor compute/communication efficiency.
Both DP and MP maintain all the model parameter values required over the entire training process, even though not all model states are needed during the training.
To overcome the limitations of DP and MP while maintaining their merit, researchers from Microsoft developed a novel approach of memory optimization called Zero redundancy Optimizers (ZeRO). Zero Redundancy Optimizers enable the training of a very large model efficiently with better training speed by eliminating the redundancies in memory used by the model.
There are three stages of optimization in ZeRO:
1. Optimizer Partitioning (Zero-Stage 1): The optimizer state contains the momentum and variance of the gradients to update the parameters for optimizers like Adam. In this stage, the optimizer state is partitioned equally among the number of devices available. Each GPU only stores a portion of optimizer states (a partition) and updates only that optimizer’s state partition and parameters during training.
2. Gradient partitioning (Zero-Stage 2): Gradients are numerical calculations that are used to adjust the parameters of the network. In Zero-Stage 1, GPUs only update the parameters corresponding to their partition. Therefore, only gradients responsible for updating corresponding parameters in the partitions are sent to the GPU during the backpropagation process.
3. Parameter Partitioning (Zero-Stage3): Parameters are the values (or weights) that are to be tuned to get a good Model. Here, just like the optimizer and gradient partition steps, only the partition of a parameter gets stored in the GPU. Parameters outside of a partition that is required during the forward and backward propagation are received from the other GPUs through broadcasting.
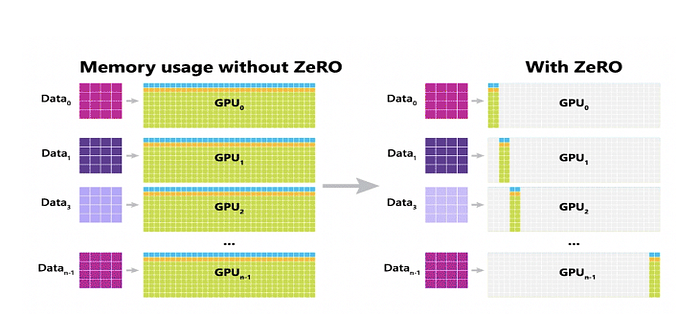
Figure 2 illustrates memory utilization on each GPU with and without ZeRO. It is observed that in standard Distributed training there is a redundancy in memory usage and causes limitation in training a very large model. However, ZeRO greatly reduces the memory usage on the GPU and enables it to fit more data and train larger models.
We have integrated Zero-Stage 3 in the below section. We combined all the stages: i.e., optimizer, gradient, and parameter partitioning, and freed up GPU’s memory by avoiding redundant memory usage caused by the model state.
Fairscale library
Fairscale library has the PyTorch implementation of Zero Optimizers and is very easy to use, and with few lines of change in the existing code, we can integrate ZERO.
Installation
To install Fairscale use the following command
pip install fairscaleIntegration of ZeR0 Stage 3
To integrate the Zero Optimization into the code base, we need to wrap the model into the Fully Sharded Data-Parallel module from Fairscale Library, which can be done in the following way.
from fairscale.nn.data_parallel importFullyShardedDataParallel as FSDP
model = Model().to(rank)
model = FSDP(model)Fairscale implementation of ZeRO also supports Pytorch Native FP16 training and is much faster than FP32 training and takes 50% less training time in our experience. Training a model in Automatic Mixed Precision Mode can be done by setting mixed_precision =True.
Following is the complete training pipeline where we demonstrate a way to initiate distributed training and train a model with Zero Stage 3 in mixed-precision mode and save it.
from fairscale.nn.data_parallel import FullyShardedDataParallel as FSDP
from fairscale.nn.data_parallel import ShardedDataParallel as ShardedDDP# initializing the Distributed environment similar to PyTorch DDP.
torch.cuda.set_device(args["local_rank"])
torch.distributed.init_process_group(backend='nccl',init_method='env://')#Zero Stage 3 shards the optimizer state internally, so optimizer should always be called before wrapping the Model into FSDP.
optimizer = torch.optim.SGD(params,lr=0.01)
model = FullyShardedDataParallel(module=model,mixed_precision=True)
loss_fn = nn.CrossEntropyLoss()
# ShardedGradScaler is used in place of GradScaler for Automatic Mix Precision training which is aware of sharding of the model states.
scaler = ShardedGradScaler()
for epoch in range(num_epochs):
for batch_idx, (data, target) in enumerate(train_loader[phase]):
data, target = data.to(device), target.to(device)
model.zero_grad()
with torch.set_grad_enabled(phase == 'train') and torch.cuda.amp.autocast(enabled=True):
outputs = model(data)
loss = loss_fn(outputs, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
# saving the model.state_dict() on all the GPUs after every epoch during training, unlike PyTorch DDP where model is saved on any GPU during validation as it causes a potential deadlock .A deadlock is a situation in which two computer programs sharing the same resource are effectively preventing each other from accessing the resource, resulting in both programs ceasing to function. The parameters are not updated during validation phase so the state can be saved during the validation phase on GPU 0.
model_state = model.state_dict()
# Optimizer state is saved using model.gather_full_optim_state_dict unlike optimizer.state_dict() in pytorch DDP.
optimizer_state = model.gather_full_optim_state_dict(optimizer)
By wrapping the model into a Fully Sharded Data parallel module, as shown above, the model gets partitioned in the way mentioned in ZerO stage 3. It would optimize the memory occupied by the model on the GPU and enable much faster training of a model with million/billion parameters.
Summary
In this blog post, we discussed different approaches to save memory on GPU using Zero redundancy optimizers and train very large size models that could not fit into GPU.
We also demonstrated a useful approach to train and save the model using the Fairscale library in Automatic Mix Precision mode.
